

Python機械学習アルゴリズム学習備忘録。今回はk分割交差検証(k Fold Cross Validation)です。
内容は、Udemy の「【世界で74万人が受講】基礎から理解し、Pythonで実装!機械学習26のアルゴリズムを理論と実践を通じてマスターしよう」で学んだ内容を自分用備忘録としてまとめたものです。
k分割交差検証と併用されることの多い、グリッドサーチ(Grid Search)も別途見ておこう。
参考
みんなのAI講座 ゼロからPythonで学ぶ人工知能と機械学習
【機械学習アルゴリズム学習備忘録】Boosting – グリッドサーチ grid search –
k分割交差検証 k Fold Cross Validation
機械学習のモデル構築の上で生まれる次のような疑問。
- モデルを構築する際にbiasとvarianceのトレードオフに対してどのように対処するか
(参考)バイアスとバリアンス(偏りと分散)のトレードオフ(Bias-Variance Tradeoff)とは? - ハイパーパラメータの適切な値をどのようにして決めるか
- 対処する問題に対してどのようにして最適なモデルを作るのか
これらの問題に対処する方法のひとつとして、
- k分割交差検証 (今回の内容)
- グリッドサーチ
があり、この2つは併用されることも多い。
上に戻るk分割交差検証の直感的なイメージ
一般的に、モデルを訓練する際、データセットを訓練用と検証用にわけて、訓練用データで訓練する。
そのとき、ハイパーパラメータを調整し、当てはまりの良いモデルを作成し、検証用データで精度を検証する。
このとき、訓練用と検証用データの分け方に偏りがある場合、偏った訓練用データでモデルが訓練されてしまう。また、検証用データのばらつきも訓練用データと同様であれあ、偏ったモデルにも関わらず、精度の高いモデルであるように見えてしまう。
その対処法として、モデル訓練でvalidation dataを用いる方法もあるが、ここではk分割交差検証を用いる方法を考える。
ポイントとしては、訓練用データセットそのものを分割するところにある。
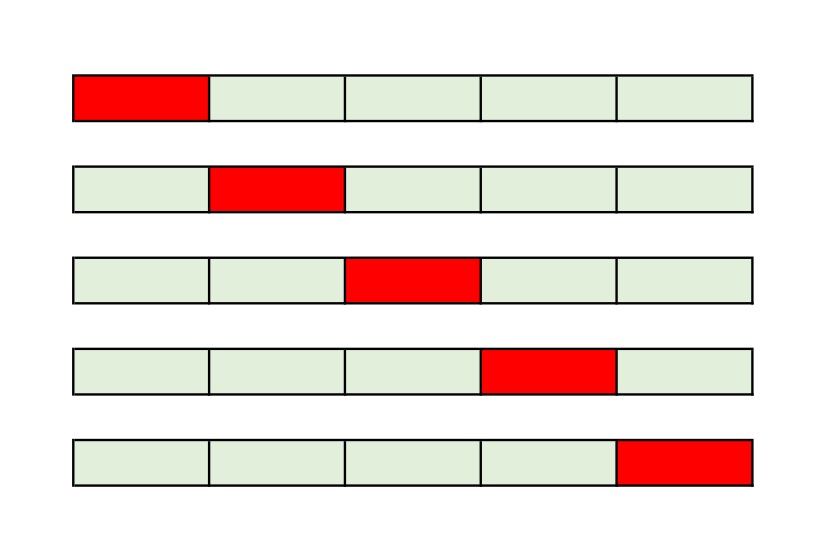
例えば、k = 5のとき。訓練用データセットを5つの塊に分割する。そのうちそれぞれの塊の中で、1つずつをテスト用データとして振り分ける。
残り4つの塊を使ってモデルの訓練を行い、先程振り分けたテスト用データを用いて検証を行う。これを5つの塊それぞれで行い、総合的に精度の高いパラメータを用いて偏りやばらつきの少ない最終的なモデルを作成していく。
上に戻るPythonによる実装
というわけで実装していく。
ライブラリのインポート
import numpy as np
import matplotlib.pyplot as plt
import pandas as pdデータセットのインポート
dataset = pd.read_csv('ファイル名.csv')
X = dataset.iloc[:, [2, 3]].values
y = dataset.iloc[:, -1].valuesフィーチャースケーリング
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X = sc.fit_transform(X)訓練用とテスト用へのデータセットの分割
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)訓練用データセットのモデルの訓練
今回はKernel SVMを使っていく。
from sklearn.svm import SVC
classifier = SVC(kernel = 'rbf', random_state = 0)
classifier.fit(X_train, y_train)テスト用データセットを使った結果の予測と混同行列の作成
y_pred = classifier.predict(X_test)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
print(cm)k分割交差検証の適用
ここからk分割交差検証を適用していく。
from sklearn.model_selection import cross_val_score
accuracies = cross_val_score(estimator = classifier, X = X_train, y = y_train, cv = 10)
# estimator : モデルの指定。今回は上で作成したKernel SVM
# X : 使用するデータ。
# 訓練用データセットを分割していくので、訓練用データセットX_trainを入れている。
# cv : cross validation. いくつの数で訓練用データを分割するか。
print('Accuracy : {:.2f) %'.format(accuracies.mean()*100))
# 10回に分けたもののaccuracyの平均(mean)を取っている。
# 次に上で出したaccuracyの平均のばらつきを見る。
# 例えば、上のaccuracyの平均が90%と出ても、10個のうち1個だけが90%以上で他が低い、
# みたいな内容だと、ばらつきが大きいすぎる。
print('Standard Deviation : {:.2f) %'.format(accuracies.std()*100))
# 出力結果はこんな感じ
# Accuracy : 90.00 %
# Standard Deviation : 6.83 %
と、こんな感じでk分割交差検証を適用していく。
上に戻る


コメント